Local models that don't leave you behind
Syzygy turns your Mac into a private AI coworker, running powerful models locally and working across your files, apps, browser, and code.
A full workday. Zero cloud inference.
Our goal is simple: an AI coworker that can handle the work you do all day without sending a single inference request to the cloud.
01
More capability per byte
The model and inference engine must deliver serious intelligence within the memory, bandwidth, and power available on personal hardware.
02
Every token has to earn its place
Space in the context window is precious for small models. Instead of relying on million-token prompts, the harness must select the right tools and context, compress old work, preserve memory, and delegate cleanly.
03
Intelligence has to reach the work
The model needs safe, permissioned access to files, apps, browsers, and code, not merely a text box.
Models worth building around
Mach-1 Small, based on Qwen3.6 35B, is a 35B-parameter multimodal mixture-of-experts model sized at only 7.7 GB, vision included, small enough for a 16 GB Mac. Paired with the Mach engine, it delivers the speed and capability required for serious agentic work.
Capability, not just compression
Speed within a local memory budget
A harness built for local intelligence
Local models benefit from a more disciplined agent loop. Our harness keeps the context focused, makes tools available only when they are useful, recovers from mistakes, and gives you precise control over every action.
Find the right tools when they're needed
The harness searches the full catalog and loads only the tools relevant to the current task. The model gets the capabilities it needs without paying the context cost of every available integration.
Make the context window go further
Older work is compacted, important facts move into memory, and independent subtasks run in isolated contexts, keeping the main prompt focused as the work grows.
Permission at the level of the action
Set individual tools to Allow, Ask, or Block, configure computer access per app, and review every tool call in the conversation. Sensitive actions stay gated without forcing you to choose between approving everything and approving every step.
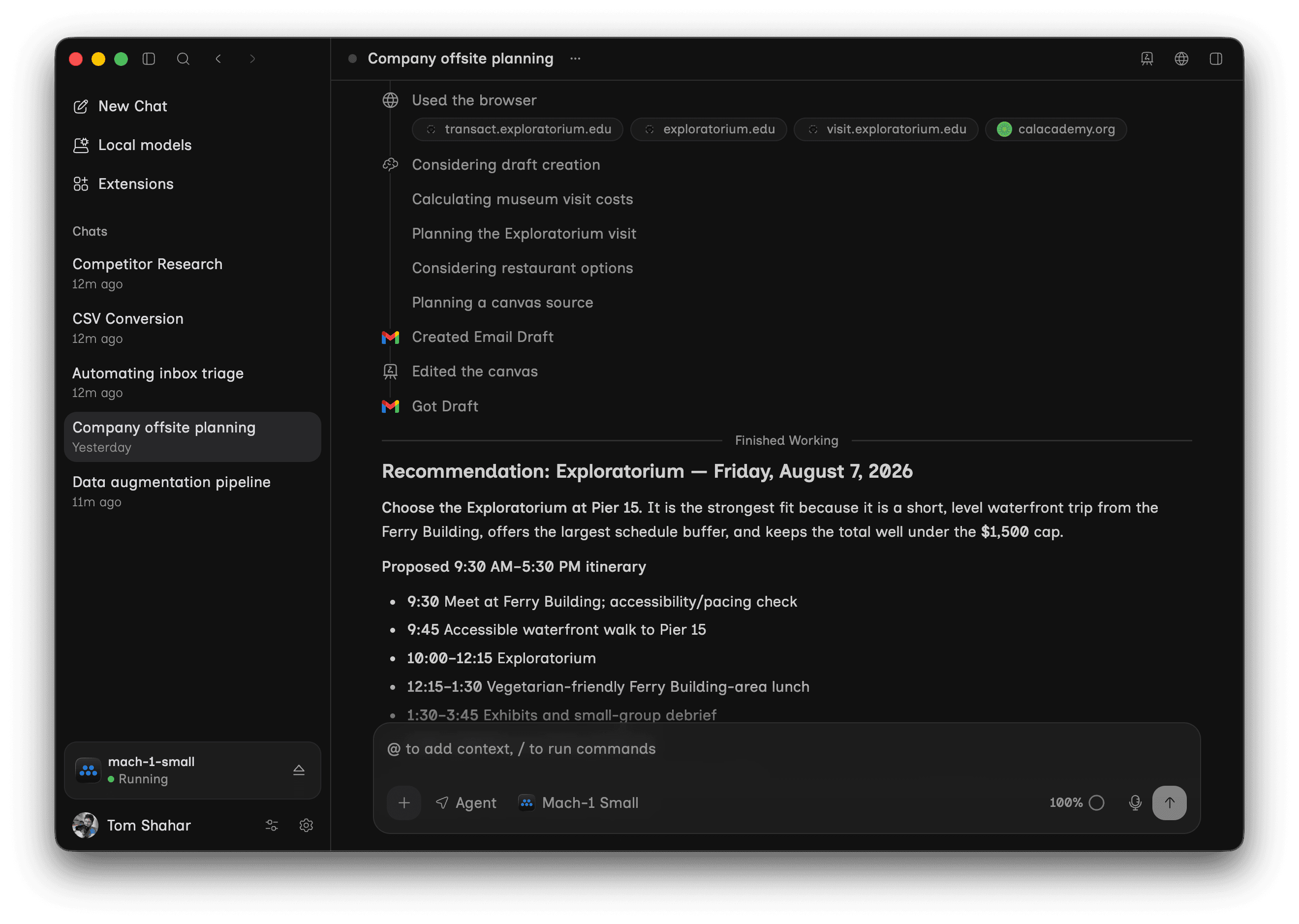
Put it to work
Mach-1 Small, the Mach engine, and our harness give a local agent the capabilities you expect from cloud agents: using your computer and browser, working across connected apps, and running recurring tasks on its own.