> This is the markdown version of https://www.maniac.ai/blog/autonomous-enterprise-ai-engineer. Visit the full page for interactive content.
# Autonomously Beating GPT-5.2 and Gemini 3 Pro in Prediction Accuracy, with 30x Cheaper Inference for Commerce AI | Maniac | Maniac
[Blog](/blog)
January 23, 2026
**TL;DR**, The customer's only input was adding hooks to capture production traffic. The output: autonomously fine-tuned, prompt-optimized Small Language Models that handle brand normalization, extraction, and sentiment analysis, achieving 90.6% accuracy on brand normalization, 12.8pp higher than GPT-5.2 and 28.0pp higher than Gemini 3 Pro on the same inputs, at a fraction of the cost.
**Why this matters beyond one customer**, The same autonomous pipeline produced all three of the customer's models, brand normalization, brand extraction, and brand sentiment, without modification. We report detailed numbers on normalization because it's the hardest of the three, but the pipeline ran identically for each task. Every stage described below, prompt optimization, data bootstrapping, rationale-guided training, massive hyperparameter sweeps, automated evaluation, is **task-agnostic**. The only inputs are (1) a rough description of the task and (2) hooks to capture production traffic. The output is a deployed, continuously improving Small Language Model that outperforms frontier models at orders of magnitude lower cost. Swap these three tasks for document classification, intent routing, compliance screening, or any structured predictive task, the pipeline runs identically.
* * *
## The Problem
Our customer needed production-grade NLP containers for three core tasks:
- **Brand Normalization**, mapping messy brand mentions ("Nike's", "Acme Pro", "mcdonalds") to canonical spellings ("Nike", "Acme", "McDonald's"), handling sub-brands, possessives, URL-to-brand conversion, and project-specific collapsing rules.
- **Brand Extraction**, identifying and extracting brand entities from unstructured content.
- **Brand Sentiment**, classifying sentiment toward extracted brands in context.
Brand normalization in particular is deceptively hard. It's not just string matching, the model needs to understand a **layered set of precedence rules**: project-specific names take priority over canonical list matches, which take priority over fallback normalization. It needs to recognize that "NICE Actimize" should normalize to "Actimize" (not "NICE") because "Actimize Case Manager" appears in the canonical list. It needs to know that "collegevine.com" is the brand "CollegeVine", that "SensaAI" is a sub-brand of "SymphonyAI", and that possessives like "Nike's" should be stripped. All of this must be applied consistently across thousands of inputs with varying formats, languages, and edge cases, and the output must be valid, structured JSON every time.
Critically, these are **predictive models, not autoregressive**, they need to generate accurate, structured responses in a single pass without chain-of-thought reasoning or "thinking" tokens. Every extra token costs latency and money, and at production scale there's no room for verbose reasoning traces. This constraint led us to **Rationale-Guided Training (RGT)**, which teaches the model _why_ during training so it doesn't need to reason at inference time.
The naive approach, calling GPT-5.2 or Gemini 3 Pro for each request, works, but it's expensive. Unlike consumer apps with bounded usage patterns, background agents have virtually unlimited potential token expenditure, they run continuously, process every incoming request, and scale with the business. Across three containers, frontier model API costs quickly become prohibitive. We needed a model that could match frontier accuracy at a fraction of the cost.
* * *
## The Solution: Fine-Tuned Qwen3-14B
We chose [**Qwen3-14B**](https://huggingface.co/Qwen/Qwen3-14B) as our base model for several reasons:
1. **Strong multilingual performance**, the customer's content spans multiple languages, and Qwen3's multilingual training data gives it a head start.
2. **Large enough to reason, small enough to serve**, 14B parameters hits the sweet spot between capability and inference cost on a single GPU.
3. **Native support for structured output**, critical for JSON schema-constrained responses like `{"mappings": [{"original": "...", "normalized": "..."}]}`.
### Cost Comparison
Model
Cost per 1M tokens (input/output)
Relative Cost
GPT-5.2
$1.75 / $14.00
Baseline
Gemini 3 Pro
$2.00 / $12.00
~0.9x
**Qwen3-14B (self-hosted)**
**$0.06 / $0.06**
**~30–230x cheaper**
Crucially, all three containers, brand normalization, brand extraction, and brand sentiment, are served from a **single Qwen3-14B base model** on a single GPU. Each container is a lightweight [LoRA](https://arxiv.org/abs/2106.09685) adapter (a few hundred MB) that gets **hotswapped onto the base model at request time** via [vLLM's dynamic LoRA loading](https://docs.vllm.ai/en/latest/features/lora.html). The base model stays resident in GPU memory; only the small adapter weights are loaded and unloaded as requests arrive for different tasks.
* * *
## Training Pipeline: GEPA → Bootstrap → RGT → SFT
Our training pipeline has four stages, orchestrated as a **single end-to-end workflow that requires zero human intervention** once pointed at a task. Every stage is parameterized by the task description and production data, nothing is hardcoded to brand normalization. The same pipeline produced all three of the customer's containers (normalization, extraction, sentiment) without modification.
### Stage 1: GEPA Prompt Optimization
Before generating any training data, we need a precise, optimized system prompt. A vague or underspecified prompt leads to high variability in response quality, the frontier model might interpret the task differently across examples, producing an inconsistent dataset that the fine-tuned model inherits.
**GEPA** (built on [DSPy](https://github.com/stanfordnlp/dspy)'s prompt optimization framework) solves this by automatically refining the system prompt against a held-out evaluation set:
1. Start with an initial system prompt describing the task (e.g., "You are a brand name normalization expert...").
2. GEPA treats the prompt as a learnable parameter. It generates candidate prompt variations, evaluates each against a validation set using a Gemini-based judge ("Is the response accurate in answering the input with respect to the system prompt?"), and iteratively refines based on feedback from a teacher model.
3. The optimizer explores prompt rewrites iteratively, using a reflection LM (Gemini 3 Pro) to analyze failures and suggest improvements.
4. The best-performing prompt is saved and used going forward.
For example, our brand normalization prompt grew from a simple instruction into a detailed 3,300-character specification with explicit precedence rules (project name collapsing > canonical list matching > fallback normalization), sub-brand handling, URL-to-brand conversion, and casing rules, all discovered automatically by the optimizer. Here's the full optimized prompt:
View the GEPA-optimized system prompt for brand normalization
You are a brand name normalization expert. Your task is to match brand names to their canonical spellings.
Here are the detailed rules and guidelines you must follow, in order of precedence:
**1\. SPECIAL RULE FOR PROJECT NAME:**
- The project name will be provided in the input.
- If you encounter this exact project name OR any sub-brand, product variant, or related entity normalize it to just the project name.
- Examples: "GitHub Copilot" → "GitHub", "Slack Connect" → "Slack", "Zoom Rooms" → "Zoom".
**2\. MATCHING AGAINST THE CANONICAL SPELLING LIST:**
- **Exact Match:** If a brand name from the `Brands to normalize` list has an exact match in the `Canonical spelling list`, use that exact canonical spelling.
- **Core Brand Match (from canonical list entries):** The `Canonical spelling list` may contain entries that are products or services of a larger brand (e.g., "Actimize Case Manager" where "Actimize" is the core brand). If an input brand name contains or is a variant of such a core brand found within a canonical entry, normalize it to that core brand.
- Example: If "Actimize Case Manager" is in the canonical list, and the input brand is "NICE Actimize", normalize "NICE Actimize" to "Actimize".
- **Similar Match (Possessives/Minor Variations):** If a brand name is a possessive form or has minor variations of a name in the `Canonical spelling list` (e.g., "Nike's" vs "Nike"), use the canonical version.
**3\. FALLBACK NORMALIZATION (If no match in the canonical list):**
- If no match or similar match is found in the `Canonical spelling list` (after applying rules 1 and 2), normalize the brand name to its most common and proper spelling. This involves several sub-rules:
- **Product/Sub-brand Variants:** If the brand name is a product, sub-brand, or specific feature of a larger, identifiable brand (e.g., "CollegeVine Admissions Calculator", "Niche app"), normalize it to its base brand (e.g., "CollegeVine", "Niche"). Use the `Content` section for context to identify such relationships (e.g., "SymphonyAI (SensaAI)" indicates "SensaAI" should normalize to "SymphonyAI").
- **URLs to Brand Names:** If the brand name is presented as a URL (e.g., "collegevine.com", "parchment.com"), normalize it to its proper brand name (e.g., "CollegeVine", "Parchment").
- **Correct Casing and Common Misspellings:** Normalize to the standard, proper casing and spelling (e.g., "mcdonalds" → "McDonald's", "APPLE" → "Apple").
- If none of the above apply and the original spelling is already proper, keep it as is.
**Content for Reference:**
- The `Content` section is provided to give you context on how brands appear in real-world text. Use this information to help identify sub-brands, product variants, or confirm proper spellings, especially when applying the fallback normalization rules.
**Output Format:** Return a JSON object with the following structure:
code
```
{
"mappings": [
{"original": "Nike's", "normalized": "Nike"},
{"original": "Adidas", "normalized": "Adidas"}
]
}
```
Ensure the `original` key contains the brand name exactly as it appeared in the `Brands to normalize` list.
This optimized prompt serves double duty: it's used as the system prompt during data bootstrapping (so training examples are consistent and high-quality), and it's the same prompt deployed to the fine-tuned model at inference time (so there's no train/serve mismatch).
### Stage 2: Data Bootstrapping
With the optimized prompt in hand, we bootstrap high-quality (input, output) pairs using Qwen3-14B itself rather than hand-labeling thousands of examples:
1. **Collect real inputs** from the customer's production traffic.
2. **Generate outputs** using Qwen3-14B with the GEPA-optimized system prompt.
3. **Validate each output** with a separate judge model (Gemini 3 Flash). When an output fails, the teacher generates a **guardrail**, a concise explanation of what went wrong (e.g., "sub-brand entries in the canonical list should normalize to the core brand, not the parent company"). That guardrail is fed back to Qwen3-14B, which re-generates with the correction. This loop repeats up to 10 iterations until the output passes.
4. **Insert the passing pairs** as training data, along with the guardrails that were generated during validation.
This gives us a dataset of ~2,000 verified examples per task, with a built-in quality floor enforced by the iterative teacher-student validation loop. Critically, the guardrails produced during bootstrapping are the same guardrails used in Rationale-Guided Training (Stage 3), they're not throwaway feedback, they become the training signal that teaches the model _why_ each answer is correct. Because every example was generated from the same optimized prompt by the model itself, the training signal is consistent, the model learns one clear set of rules rather than averaging over ambiguous interpretations.
### Stage 3: Rationale-Guided Training (RGT)
Standard SFT teaches the model to produce the right output, but it doesn't teach _why_. Chain-of-thought approaches fix this by generating explicit reasoning, but they waste tokens at inference time, you're paying for the model to "think out loud" on every request.
**RGT** ([Parsed Research](https://parsed.com/research/upweight-the-strategy-not-the-tokens-faster-training-with-explicit-reasoning)) takes a different approach: **teach the model strategies during training, but don't require it to produce them at inference time.**
Here's how it works:
**During training**, for each example, we generate two synthetic training pairs. Here's a concrete example from brand normalization, say the input contains the brands "NICE Actimize" and "Acme Copilot", and the canonical spelling list includes "Actimize Case Manager":
**Pair A (inference mode):**
> `` `` `{"mappings": [{"original": "NICE Actimize", "normalized": "Actimize"}, {"original": "Acme Copilot", "normalized": "Acme"}]}`
**Pair B (strategy mode):**
> `` _guardrail: When a canonical entry is a sub-brand (e.g., "Actimize Case Manager"), normalize to that core brand, not its parent company_ `` `{"mappings": [{"original": "NICE Actimize", "normalized": "Actimize"}, {"original": "Acme Copilot", "normalized": "Acme"}]}`
Both pairs produce the same correct output. But Pair B encodes the _decision that matters_, the hinge point where someone would most likely go wrong on this specific input.
As the model trains over hundreds of examples, these guardrails stack. One example teaches "sub-brand entries in the canonical list take precedence over parent companies." Another teaches "possessive forms should be stripped." Another teaches "URLs like collegevine.com normalize to the brand name CollegeVine, not the domain." The model internalizes a layered set of rules, not by memorizing a massive system prompt, but by repeatedly seeing the mistake it should avoid and the guardrail that prevents it.
The strategy distillation process itself is automated, and critically, **Qwen3-14B bootstraps its own RGT samples**. The base model generates the step-by-step rationales, and then a teacher model distills those into the concise guardrails:
1. For each training example, Qwen3-14B generates step-by-step reasoning for how the output was produced.
2. A teacher model analyzes that reasoning and distills it into a concise **mistake/guardrail pair**, the single most important decision point for that specific input.
3. The original example, the Pair A variant, and the Pair B variant are interleaved in the training data.
**At inference time**, we automatically inject an empty think block into the generation prompt by patching the tokenizer's chat template. The model sees the same empty-block pattern it learned from Pair A, activates the internalized strategies it accumulated from hundreds of Pair B examples, and produces the correct output, without wasting a single token on explicit reasoning. The result: **frontier-level accuracy without the latency or cost penalty of chain-of-thought.**
### Stage 4: Supervised Fine-Tuning
With the RGT-augmented dataset, we fine-tune Qwen3-14B using [**LoRA** (Low-Rank Adaptation)](https://arxiv.org/abs/2106.09685) with a hyperparameter sweep:
Parameter
Values
LoRA rank
16, 32, 64
LoRA alpha
128
Learning rate
5e-5, 8e-5
Target modules
q, k, v, o, gate, up, down projections
Optimizer
Paged AdamW 8bit
Schedule
Cosine with 5% warmup
Epochs
3
Max sequence length
20,000 tokens
That's 6 configurations (3 ranks × 2 learning rates), but in practice, we run far more. The whole point is that **no AI engineer needs to sit there experimenting** with hyperparameters. We let the system explore massively and pick the winners automatically.
**PackSFT** (our in-house training framework, [pack-sloth](https://github.com/ManiacIncorporated/pack-sloth)) makes this possible. It packs **up to 16 LoRA adapters onto a single GPU** and trains them simultaneously, **amortizing the base model's forward and backward pass across all adapters that share the same rank**, with only **2.3x slower training** compared to a single adapter. That's a **7x cost reduction** versus running each configuration independently.
Here's the key insight: in a LoRA training step, the overwhelming majority of compute goes to the base model. The frozen 14B parameters produce activations on the forward pass and receive gradient signals on the backward pass, this is identical regardless of which LoRA adapter is active. Only the low-rank delta matrices (the A and B projections) differ between configurations. PackSFT exploits this by:
1. **Grouping adapters by LoRA rank**, configs with rank 16, 32, and 64 form three groups.
2. **Sharing the base model forward pass**, within each rank group, the base model activations are computed once and reused across all adapters.
3. **Computing adapter-specific gradients in parallel**, each adapter's LoRA weights receive independent gradient updates (with their own learning rate, scheduler state, etc.), but the expensive base model computation happens only once per group.
4. **Pruning underperformers mid-training**, at each checkpoint, PackSFT can drop adapters that fall below a performance threshold, freeing memory and compute for the surviving configurations.
The result: massive hyperparameter sweeps that would normally require a team of ML engineers manually iterating become fully automated. PackSFT squeezes 16 models into one GPU, explores the search space exhaustively, and promotes the top 3 configurations (by eval accuracy across 10 checkpoints) to production, no human experimentation required. This is the same for every task: the sweep configuration is task-agnostic, and the eval suite (described below) handles task-specific quality gating automatically.
* * *
## The Eval Suite
Fine-tuning is only as good as your ability to measure it. We built a comprehensive evaluation system with four layers:
### 1\. Checkpoint Evals (during training)
Every time a LoRA checkpoint is saved during SFT, an evaluation run is automatically triggered. This gives us an accuracy curve across training, we can detect overfitting early and pick the optimal checkpoint.
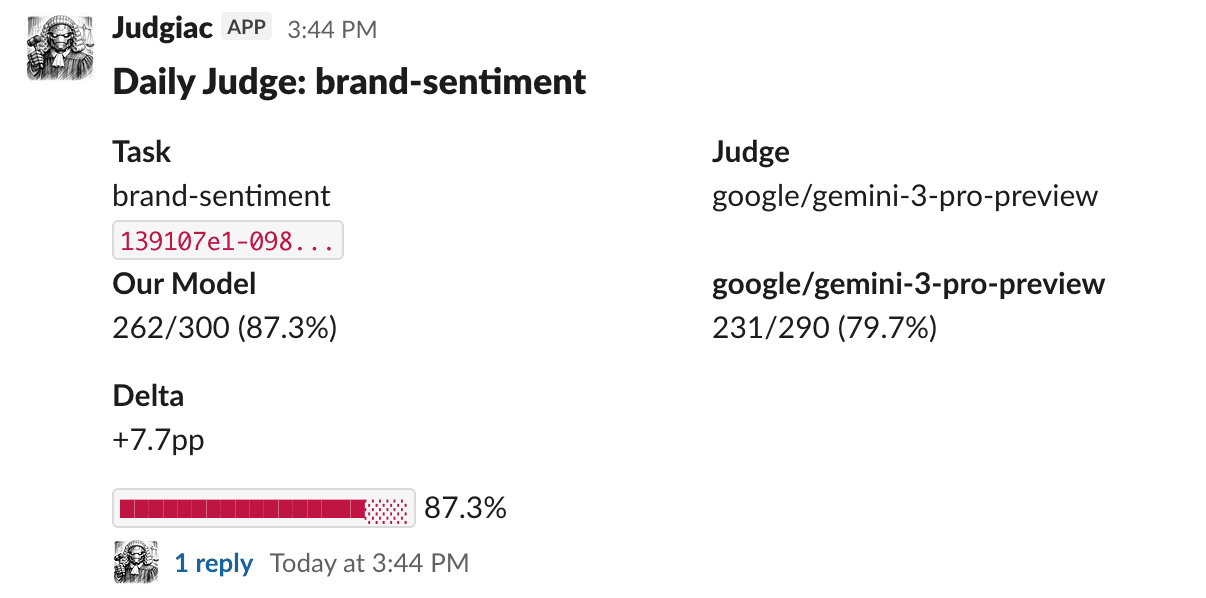
### 2\. Daily Judge (automated monitoring)
A daily cron job pulls the last 300 production inference logs for each task and judges them in two ways:
- **Our model's outputs** are evaluated by Gemini 3 Pro: _"Does the output answer the system prompt and input correctly?"_
- **Baseline outputs** are generated by sending the same inputs to Gemini 3 Pro (via [OpenRouter](https://openrouter.ai)), then judged with the same prompt.
This produces a daily accuracy comparison, our model vs. the frontier baseline on the same inputs, posted to Slack with per-bucket breakdowns (accuracy across 100-row segments), top failure reasons, and an LLM-generated weakness analysis. This catches regressions before they reach users.
### 3\. Standalone Evals (on-demand)
For deeper analysis, comparing multiple model versions, running against specific datasets, or evaluating frontier models side-by-side, we trigger standalone evaluation runs through our API. Items are judged in parallel and results land in a dashboard with per-eval accuracy, pass/fail counts, and per-item breakdowns.
### The Judge
All evaluation layers use the same judging core: a Gemini 3 Pro-based binary judge (with Flash fallback) that asks a single question, _"Does the output answer the system prompt and input correctly?"_, and returns a yes/no verdict with a one-sentence reason.
Binary verdicts are intentional. Float-score rubrics introduce noise and make it hard to compare across runs. A clean pass/fail gives us a reliable accuracy metric, and the one-sentence reason gives us actionable failure analysis.
* * *
## Results
We ran four evaluations on 300 recent production inputs for brand normalization, all judged by Gemini 3 Pro with a binary correctness verdict ("Does the output answer the system prompt and input correctly?").
Model
Training
Accuracy
Errors
**Qwen3-14B**
**RGT + SFT**
**90.6%** (270/298)
2
Qwen3-14B
SFT only
87.3% (262/300)
0
GPT-5.2
,
77.8% (231/297)
3
Gemini 3 Pro
,
62.6% (144/230)
70
The RGT-trained model outperforms SFT-only by +3.3pp, and beats both frontier baselines decisively, +12.8pp over GPT-5.2 and +28.0pp over Gemini 3 Pro. GPT-5.2 handled the structured output format reliably (only 3 errors), but consistently made normalization logic mistakes, failing to apply sub-brand rollup rules and canonical spelling matches. Gemini 3 Pro struggled more fundamentally, 70 of its 300 responses were incomplete or truncated, and of the 230 it completed, only 62.6% were judged correct.
In a head-to-head between the two Qwen3-14B checkpoints, the RGT model was correct **18 times** versus **11 times** for SFT-only on inputs where they disagreed, a nearly 2:1 win rate on the hardest examples.
Key findings:
- **90.6% accuracy on brand normalization**, the fine-tuned Qwen3-14B model achieves over 90% on a binary correctness judge, evaluated against the same GEPA-optimized system prompt used in production. This is 12.8pp higher than GPT-5.2 and 28.0pp higher than Gemini 3 Pro on the same inputs, frontier models that cost orders of magnitude more per request.
- **+3.3pp from RGT**, Rationale-Guided Training added 3.3 percentage points over the SFT-only baseline, while producing zero extra tokens at inference time. The accuracy gain comes entirely from internalized strategies, not from chain-of-thought verbalization.
- **Cost reduction**, all three containers (brand normalization, extraction, sentiment) run on a single GPU with LoRA hotswapping, replacing what would otherwise be three separate frontier model API subscriptions. At the customer's request volume, this translates to an order-of-magnitude reduction in per-request cost compared to GPT-5.2 or Gemini 3 Pro pricing.
* * *
## Lessons Learned
**1\. Bootstrap quality > bootstrap quantity.** Our grade-and-retry loop (up to 10 iterations with progressively stronger models) was more impactful than simply scaling up the dataset. 2,000 high-quality examples outperformed 10,000 unfiltered ones.
**2\. RGT is real.** Teaching the model _why_ through strategy distillation, then not requiring it to verbalize that reasoning, gave us +3.3pp over standard SFT without any additional inference cost. On the inputs where the two approaches disagreed, RGT won nearly 2:1. The mistake/guardrail format is particularly effective for structured tasks where there's a clear "most likely error" per input.
**3\. Continuous eval is non-negotiable.** The daily judge caught two regressions in the first month that would have gone unnoticed with periodic manual testing. Automated, daily, Slack-posted accuracy comparisons against a frontier baseline keep the team honest.
**4\. LoRA sweep > single config.** Our hyperparameter sweep across LoRA ranks (16/32/64) and learning rates consistently found configurations that beat the "reasonable defaults" by 2-5pp. The cost of running the sweep on a single H100 is negligible compared to the accuracy gain.
* * *
## What's Next: Continual Learning Across Every Task
Because every stage of this pipeline, prompt optimization, data bootstrapping, RGT, hyperparameter sweeps, evaluation, is fully autonomous and task-agnostic, it naturally enables **continual learning at scale**. As new production data flows in, the pipeline can re-bootstrap training examples from the latest inputs, re-run RGT to internalize new edge cases, and sweep fresh adapter configurations, all without an engineer in the loop. The daily eval suite catches regressions automatically, so the model improves over time as the data distribution shifts, rather than silently degrading.
This is what makes it an **autonomous AI engineer**, not just a training script. Point it at any predictive task with production traffic, and it autonomously produces a deployed model that outperforms frontier APIs, then keeps that model sharp as the world changes around it. No ML team. No manual experimentation. Just hooks and a task description.
* * *
_Built with [Modal](https://modal.com) for compute, [Supabase](https://supabase.com) for data, [vLLM](https://docs.vllm.ai) for inference, and a lot of [Gemini](https://ai.google.dev/gemini-api/docs) tokens for judging._
---
*Maniac, High throughput background agents. Opus-quality outputs at 1/50 of the cost. Learn more at [maniac.ai](https://www.maniac.ai).*